How it works¶
Overview¶
This automatic toolbox for image processing is current build on AWS. The main computational work is done on Amazon EC2 Container Service (Amazon ECS). In our case, each image processing job (processing one file/image using one algorithm) is launched into separate ECS tasks on the ECS cluster, which can be scaled perfectly.
Normally, an image processing work flow contains multiple algorithms and intermediate data transfer from one algorithm to another. This tool will also handle that for the users. All the intermediate data are stored in the S3 bucket for transfer and possible later use of users.
This tools also facilitates researchers to bring their own algorithms. To use your own algorithm, simply prepare it inside a Docker container, and push the image to Docker Hub or locally. Then, by using the container wrapper tool, you can describe all the details of your algorithm: including its command line options, user defined variables and required resources to run it.
The following is the Amazon services we use to construct this automation:
- Amazon EC2 Container Service (ECS): In our case, this is the platform of all computational work.
- AWS Lambda : AWS Lambda is a compute service that runs code in response to events. We use this to trigger the actual image processing tasks.
- AWS S3:
- AWS Simple Queue Service (SQS): SQS is a fast, reliable, scalable, fully managed message queuing service.
- AWS CloudWatch: Amazon CloudWatch is a monitoring service for AWS cloud resources and the applications you run on AWS. We use this to collect running logs, monitor and terminate idle EC2 instances.
Wrap¶
In the area of imaging processing, researchers use various different algorithms to processing images. Therefore it is crucial to allow users to bring their own algorithm into the work flow. This tool make it very easy to integrating customer own tools, simply installed inside Docker containers and described their behavior precisely using our command line editor or, if user prefer, via a JSon document that can easily imported.
With the information of the algorithm and the containerized algorithm, a new container with a running script is generated. This container is the actual container when the algorithm is used. The running script handles all the hassles to run the processing job: retrieving input information from SQS, downloading input object from S3 bucket, putting input object to correct location, running the processing job, uploading the result object to designed location and managing logs throughout the whole process.
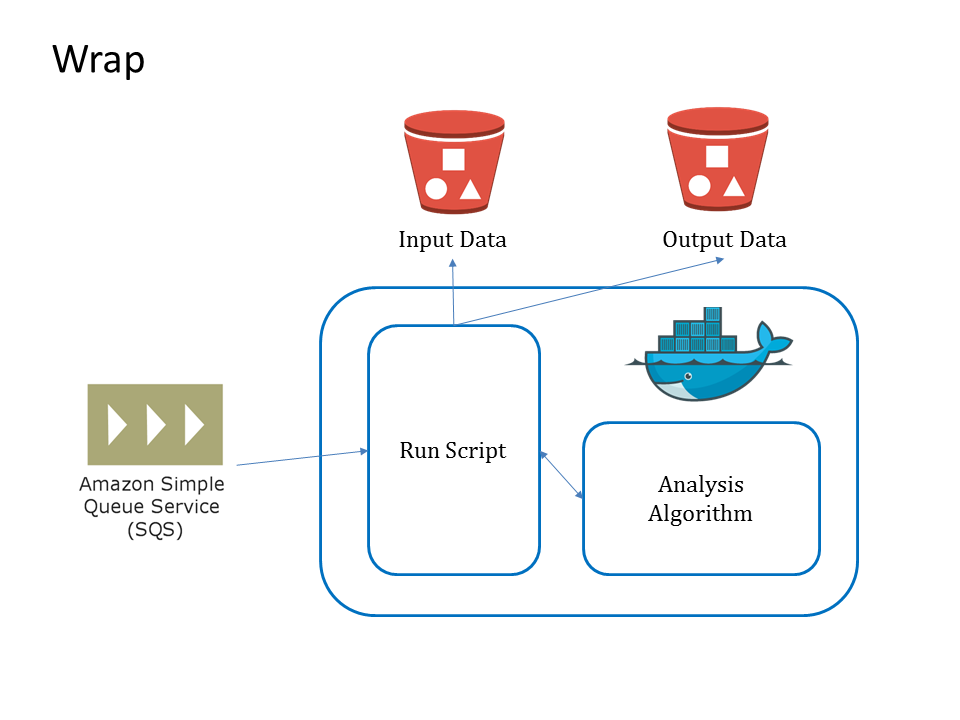
Run¶
To achieve high scalability, we disassemble complex work flow into two part: single algorithm processing and information transfers between algorithms.
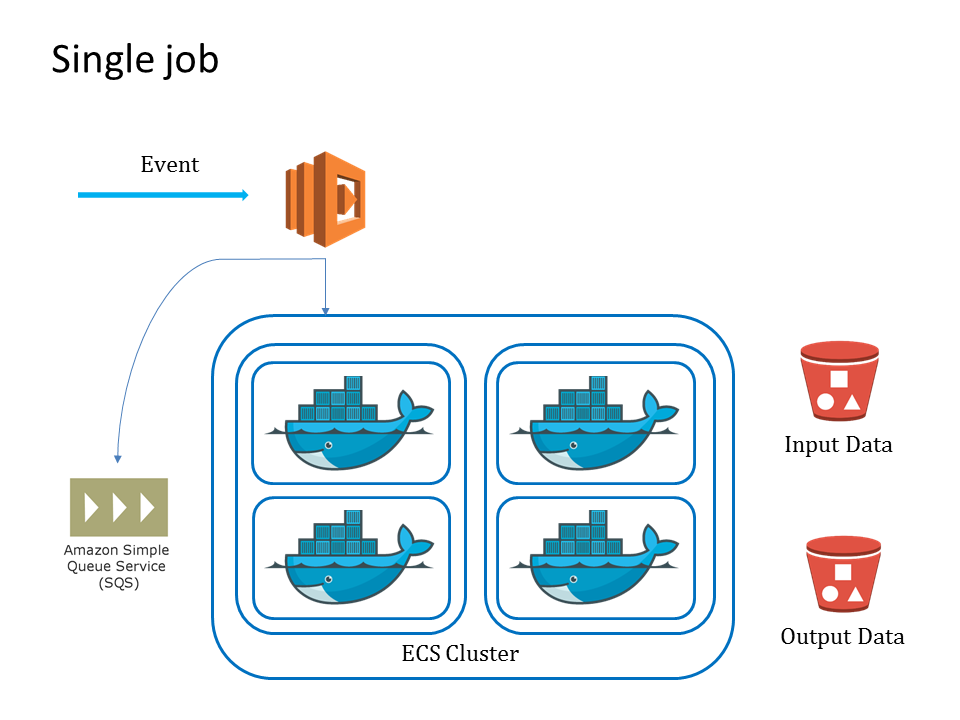
For each single algorithm processing, a microservice is built around it on AWS:
- a lambda function is used to monitor the input event. It can be triggered by a file upload to the input file s3 bucket event or invoked by called from other lambda functions. Once it is triggered, it send the information of the input file to a message queue and start a ECS task to start algorithm processing.
- a message queue, we use Amazon Simple Queue Service (SQS) in the current version, is used to hold the information about the input files.
- a ecs task is used to perform the actual algorithm processing on the cloud. It retrieve the input file information from the message queue, download from sources and process the files. Once it is finished, the resulting file is upload to another s3 bucket and the ecs task is terminated.
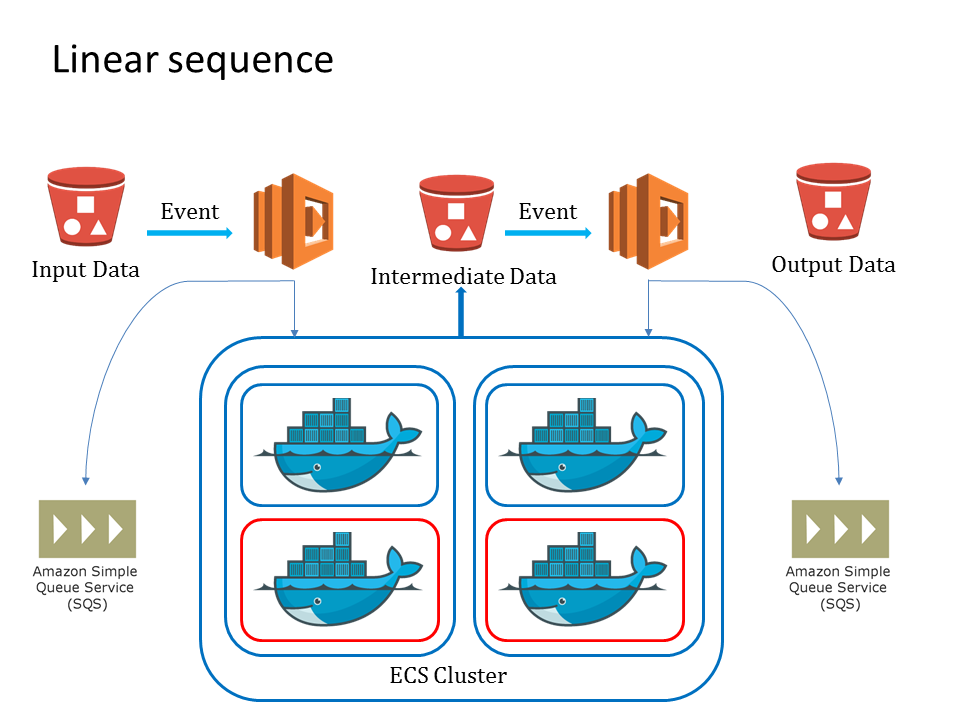
Yunpipe also supports sequential analysis pipeline. The intermediate data is also stored in s3 bucket, which is also used as the launch event for the next analysis step.
As each task is run on specific type of EC2 instance, the default ECS scheduler does not fit our need. In our current version, lambda function is also in charge of checking resources to start ecs task, launch ec2 instance into ecs cluster if needed and register ec2 on cloudwatch for shutdown. This is not very efficient. In our future version, a customer scheduler will be added the substitute that part in lambda function.